
Ab jetzt wird gehaftet, Vibe Coder: Die EU-Produkthaftungsrichtlinie 2024/2853
2026-04-26

Autor: Jens Henneberg
Stand: 2026-04-26 - 12:00
Stell dir vor, du baust eine App, die bei der Insulingabe helfen soll. Blutzucker rein, Dosis raus. Das Ganze funktioniert KI-gestützt. Darunter steht, wie auf fast jedem KI-Gadget, der rituelle Hinweis: „KI kann Fehler machen." (ein bisschen so wie die Horror-Bildchen auf den Zigarettenschachteln)
Eine erfahrene Ärztin nutzt die App. Die Werte werden manuell eingegeben. Die App rechnet. Und irgendwo im Code stolpert ein Ausführungsfehler über seine eigenen Schnürsenkel.
Die Empfehlung ist falsch. Die Ärztin, wie immer im Stress, folgt ihr. Die Patientin landet daraufhin in der Notaufnahme.
Was war los?
Ein Softwarefehler.
Manifestiert als Körperschaden.
Kein Bildschirm ist kaputt, kein Kabel ist in Brand geraten, nein, eine Patientin musste in die Notaufnahme.
Genau solche Fälle sind der Grund, warum die europäische Produkthaftung neu justiert wird. Die Richtlinie (EU) 2024/2853 räumt mit der bequemen Annahme auf, Software und KI-Systeme seien haftungsrechtlich nur immaterieller Nebel mit Benutzeroberfläche. Software ist ausdrücklich als Produkt erfasst. Das gilt auch dann, wenn sie als Software-as-a-Service bereitgestellt wird oder als KI-System in eine größere Anwendung eingebettet ist.
Für Hersteller, Entwickler und CTOs ist das kein Randthema (mehr). Wer ein Produkt auf dem europäischen Markt in Verkehr bringt, bereitstellt oder in Betrieb nimmt, muss sich an europäischen Haftungsregeln messen lassen. Das ist Binnenmarktlogik: gleiche Spielregeln für alle, die auf diesem Markt anbieten. Auch für Anbieter aus Drittstaaten. Auch für Anbieter aus den USA. Ein Unternehmenssitz in Delaware ist kein haftungsrechtlicher Tarnmantel.
Dogmatisch muss man sauber bleiben: Die Richtlinie (EU) 2024/2853 ist keine Verordnung. Sie gilt daher nicht wie der EU AI Act unmittelbar in allen Mitgliedstaaten, sondern muss national umgesetzt werden. In Deutschland soll das derzeit über den Regierungsentwurf BT-Drs. 21/4297 erfolgen. Die neuen Regeln sollen für Produkte gelten, die nach dem 9. Dezember 2026 in Verkehr gebracht oder in Betrieb genommen werden.
Daraus folgt die These dieses Artikels: Die neue Produkthaftung macht KI-Haftung zu einem Architekturproblem. Wer Modellverhalten, Datenherkunft, Updates, Logs und Betriebsentscheidungen nicht beweisfähig rekonstruieren kann, verliert nicht erst im Audit, sondern im Haftungsprozess.
Die Black Box verschiebt sich damit vom klägerischen Beweisproblem zum existenziellen Risiko des Herstellers.
SOFTWARE IST EIN PRODUKT, EGAL WOHER SIE KOMMT UND WIE SIE INTEGRIERT IST
Art. 4 Nr. 1 RL (EU) 2024/2853 bestimmt:
„Produkt bezeichnet jede bewegliche Sache, auch wenn diese in eine andere bewegliche oder unbewegliche Sache integriert oder damit verbunden ist; unter Produkt sind auch Elektrizität, digitale Konstruktionsunterlagen, Rohstoffe und Software zu verstehen."
Damit ist Software ausdrücklich im Produktbegriff angekommen. Kein dogmatisches Herumtasten mehr, kein Streit darüber, ob ein Programm körperlich genug ist, um Produkthaftung auszulösen. Der Gesetzgeber zieht Software in das Regime der verschuldensunabhängigen Produkthaftung.
Erwägungsgrund 13 macht den Punkt noch schärfer: Software kann körperlich oder nicht-körperlich sein, als eigenständiges Produkt in Verkehr gebracht oder später als Komponente integriert werden. Genannt werden ausdrücklich Betriebssysteme, Firmware, Computerprogramme, Anwendungen und KI-Systeme. Entscheidend ist nicht, ob die Software lokal installiert ist, über ein Kommunikationsnetz abgerufen wird, aus der Cloud kommt oder als Software-as-a-Service bereitgestellt wird.
Die neue Richtlinie beendet die bisherige Unsicherheit zur Einordnung von Software und stellt klar, dass die Art der Bereitstellung oder Nutzung keine Rolle spielt.
Für KI-Anwendungen ist das entscheidend. Eine KI-gestützte App, die lokal läuft, ist Software. Eine KI-gestützte App, die als SaaS läuft, ist ebenfalls Software. Ein KI-System, das in eine größere Anwendung eingebettet ist, verschwindet nicht aus dem Haftungsrecht, nur weil es keinen Schraubenkopf hat.
Art. 4 Nr. 4 RL (EU) 2024/2853 definiert Komponente als jeden körperlichen oder nicht-körperlichen Gegenstand, Rohstoff oder verbundenen Dienst, der in ein Produkt integriert oder mit dem Produkt verbunden ist. Art. 8 Abs. 1 lit. b sieht die Haftung des Herstellers einer fehlerhaften Komponente vor, wenn diese Komponente unter der Kontrolle des Herstellers in ein Produkt integriert oder damit verbunden wurde und die Fehlerhaftigkeit des Produkts verursacht hat.
Hinzu kommt, dass bei Fehlern integrierter Software nicht nur der Endhersteller, sondern auch der Softwarehersteller in Anspruch genommen werden kann.
Das ist für KI-Architektur der nächste Sprengsatz.
Denn moderne KI-Produkte bestehen selten aus einem monolithischen Stück Software. Sie bestehen aus Modellen, APIs, Cloud-Diensten, Datenpipelines, Embeddings, Front-Ends, Monitoring, Update-Mechanismen und oft aus fremden Komponenten. Produkthaftungsrechtlich stellt sich dann nicht nur die Frage:
Ist das Produkt fehlerhaft?
Sondern auch:
Welche Komponente hat die Fehlerhaftigkeit verursacht, wer hat sie integriert, und wessen Kontrolle unterlag sie?
CODE IST NICHT GLEICH SOFTWARE

Hier liegt die erste Grenze, und sie ist entscheidender, als sie auf den ersten Blick wirkt.
Art. 4 Nr. 1 RL (EU) 2024/2853 erfasst Software ausdrücklich als Produkt. Daraus folgt aber nicht, dass jede digitale Datei, jeder Text, jeder Quellcode und jede KI-Ausgabe automatisch selbst ein Produkt wäre.
Erwägungsgrund 13 zieht die Trennlinie: Software kann Produkt sein, Informationen nicht. Deshalb sollen die Produkthaftungsvorschriften nicht für den Inhalt digitaler Dateien gelten, etwa für Mediendateien, E-Books oder den reinen Quellcode.
Das ist trocken, aber es ist der dogmatische Sicherungskasten des ganzen Arguments.
Denn „Code" ist als Sammelbegriff unscharf. Für die Einordnung muss man ihn auseinanderziehen. Mindestens drei Ebenen sind zu unterscheiden:
| EBENE | PRODUKTHAFTUNGSRECHTLICHE EINORDNUNG |
|---|---|
| Reiner Quellcode | als Information grundsätzlich nicht Produkt |
| Maschinenausführbare Software | Produkt im Sinne von Art. 4 Nr. 1 RL (EU) 2024/2853 |
| KI-generierter Output | nicht selbst Produkt, kann aber Fehlerbild einer fehlerhaft ausgeführten Software sein |
Brenner bringt die Konsequenz auf den Punkt: Quellcode ist zunächst Information; als solche fällt er nicht in den Anwendungsbereich der Produkthaftungsrichtlinie. Der Softwarebegriff der Richtlinie erfasst dagegen nur die maschinenausführbare Codierung. Wird Quellcode jedoch einem Hersteller überlassen, von diesem in ein Produkt überführt und dort eingesetzt, kann der Softwareentwickler wegen Fehlern im Quellcode gleichwohl als Hersteller einer fehlerhaften Komponente in Anspruch genommen werden (Brenner, Raphael. „Software im Fokus der neuen Produkthaftungsrichtlinie". Recht Digital (RDi), 2024, 345–52).
Damit ist die Trennlinie klar: Nicht jeder „Code" ist im haftungsrechtlichen Sinn Software. Aus Quellcode kann aber Software werden. Und sobald diese Software bestimmungsgemäß ausgeführt wird und gerade diese Ausführung einen Schaden verursacht, sind wir im Produkthaftungsrecht.
Wir müssen hier auch aufpassen und sauber differenzieren!
Wenn die KI fehlerhaft antwortet, bspw. indem sie behauptet, das dass Krümelmonster von der Sesamstraße in Wahrheit ein menschenfressendes Alien sei, dann ist ihre Äußerung zunächst einmal einfach eine Information. Wenn auch eine fehlerhafte. Oder aber ich habe als Kind immer nur die jugendfreie Version gesehen.
Bei Antworten von KI ist nicht die Information das Produkt! Ganz wichtig:
Information bleibt einfach Information.
Wenn die KI falsch funktioniert, gibt sie vielleicht eine falsche Antwort. Dann liegt der Fehler bei der Software.
Die Information selbst ist also nicht das Produkt, nochmal, aber: Eine Information, die eine fehlerhaft ist, lässt darauf schließen, dass das System, also das Produkt, selbst fehlerhaft sein könnte.
Diese feinstreifige Differenzierung verhindert zwei Denkfehler.
Erstens: Nicht jede falsche Information aus einem digitalen System lässt sich in Produkthaftung „pressen". Sonst wäre jeder schlechte Gesundheitstipp, jeder Blogbeitrag mit gefährlichem Halbwissen und jede Offenbarung über Krümelmonsters geheime Alienidentität plötzlich ein Produktfehler.
Dogmatisch wäre das Unsinn, praktisch wäre es Wahnsinn.
Zweitens: Umgekehrt trägt der Hinweis „Das war doch nur Information" nicht, wenn die Information gerade Ergebnis einer fehlerhaften Softwareausführung ist und bestimmungsgemäß Grundlage einer physischen Handlung sein soll.
Kurz:
Der falsche Output ist nicht das Produkt. Er kann aber zeigen, dass das Produkt fehlerhaft gearbeitet hat.
WIE IST DAS BEI UNSERER APP?
Beim Insulin-Beispiel greift diese Unterscheidung.
Die App ist kein digitales Flugblatt, das einen schon fertigen Gesundheitstipp weiterreicht. Sie nimmt konkrete Blutzuckerwerte entgegen, verarbeitet sie und berechnet daraus eine neue Dosierungsempfehlung.
Ist diese Empfehlung wegen eines Ausführungsfehlers falsch, liegt der haftungsrechtliche Schwerpunkt nicht bei der Information als solcher, sondern bei der Ausführung des Softwareprodukts, die diese Information erst erzeugt.
Genau so argumentiert Schenk am Beispiel einer Blutzucker-App: Nach manueller Eingabe berechnet die App eine Insulindosis falsch. Es sei unbillig, die Produkthaftung von vornherein mit dem Hinweis abzuschneiden, das schädigende Verhalten sei „nur" durch eine falsche Information ausgelöst worden. Und weil KI-Systeme lediglich ein Unterfall von Software sind, soll es für diese Einordnung keinen Unterschied machen, ob die Dosierung durch KI oder durch deterministische Programmlogik ermittelt wird (Schenk, Ulrich. „Produkthaftung für falsche KI-Antworten nach der neuen Produkthaftungs-RL?“, Legal Tech Zeitschrift (LTZ), 2025, 184–90.). Sicherlich lassen sich dazu, wie immer bei Jura, auch Gegenstimmen finden. Ich aber sehe es genauso wie der Kollege Schenk.
Die Patientin ist nicht deshalb geschützt, weil KI per se „gefährlicher" wäre als klassische Software. Entscheidend ist, dass Software in einem sicherheitsrelevanten Kontext eine konkrete Berechnung erzeugt, die bestimmungsgemäß in der physischen Welt umgesetzt wird.
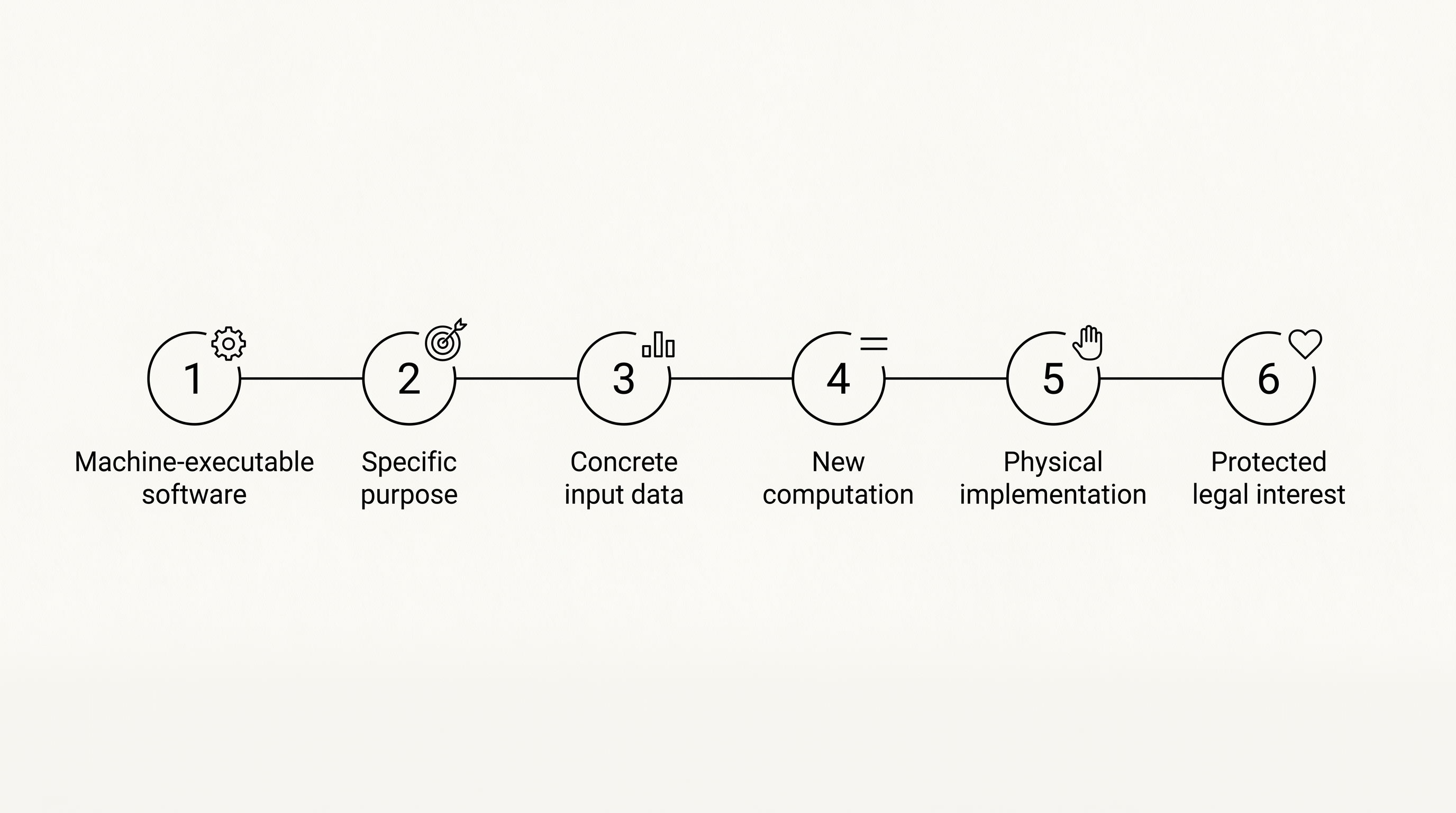
Bei der Insulin-App kommen daher mehrere Elemente zusammen:
- Maschinenausführbare Software: Die App ist Software im Sinne von Art. 4 Nr. 1.
- Spezifischer Zweck: Sie soll bei der Insulindosierung helfen.
- Konkrete Ausgangsdaten: Die Blutzuckerwerte stammen aus der Patientensphäre.
- Neue Berechnung: Die Dosisempfehlung entsteht erst durch die Ausführung.
- Physische Umsetzung: Die Empfehlung soll medizinisch umgesetzt werden.
- Geschütztes Rechtsgut: Es geht um Körperverletzung, also Art. 6 Abs. 1 lit. a RL (EU) 2024/2853.
Die App ist damit kein „Kräuterpfarrer in digital" und kein bloßer Informationsträger. Sie ist ein Softwareprodukt, das aus patientenbezogenen Daten eine Dosierungsempfehlung generiert. Ist diese Generierung fehlerhaft, geht es nicht um Informationshaftung im luftleeren Raum, sondern um Produkthaftung für fehlerhaft ausgeführte Software.
Und genau deshalb reicht der kleine Disclaimer nicht (den wir zur Zeit überall lesen, er fehlt nur noch an Joghurtbechern):
„KI kann Fehler machen."
Warnhinweise können bei der Fehlerbeurteilung eine Rolle spielen. Erwägungsgrund 31 stellt aber klar, dass Warnhinweise oder andere Informationen nicht ausreichen, um die Sicherheit eines ansonsten fehlerhaften Produkts zu gewährleisten.
Haftung lässt sich also nicht dadurch vermeiden, dass man alle denkbaren Risiken aufzählt.
WIE WÄRE DAS BEI CHATBOTS?

Bei allgemeinen KI-Chatbots liegt die Sache anders.
Das ist nicht deshalb anders, weil Chatbots keine Software wären. Natürlich sind sie das. Das Back-End, das die Antwort generiert, und das Front-End, das Prompts entgegennimmt und Antworten anzeigt, bilden bei solchen Angeboten ein einheitliches Produkt. Eine künstliche Aufspaltung würde dem Sinn von Erwägungsgrund 13 widersprechen, der Software gerade unabhängig davon erfassen will, ob sie lokal oder serverseitig ausgeführt wird.
Aber damit ist die Haftung noch nicht entschieden.
Denn die verlangt einen Fehler.
Nach Artikel 7 Absatz 1 der neuen Produkthaftungsrichtlinie (Richtlinie (EU) 2024/2853) ist ein Produkt als fehlerhaft anzusehen, wenn es nicht die Sicherheit bietet, die eine Person berechtigterweise erwarten darf oder die gesetzlich vorgeschrieben ist. Die Richtlinie stellt hierbei auf eine objektive Analyse der Sicherheit ab, die die breite Öffentlichkeit erwarten darf. Um diese Sicherheitserwartung zu ermitteln, zwingt Artikel 7 Absatz 2 zu einer Gesamtbetrachtung aller Umstände. Berücksichtigt werden müssen dabei unter anderem die Aufmachung des Produkts, die Auswirkungen seiner Fähigkeit, nach dem Release weiterzulernen, und ganz zentral: sein „vernünftigerweise vorhersehbarer Gebrauch“.
Ein KI-System ist rechtlich also nicht schon deshalb fehlerhaft, weil es lediglich eine inhaltlich falsche Information ausgibt. Eine Haftung setzt voraus, dass die falsche Information aus einer fehlerhaften Ausführung der KI (etwa durch einen Konstruktions-, Fabrikations- oder Instruktionsfehler) resultiert und dadurch diese objektiven Sicherheitserwartungen bei einem absehbaren Einsatz enttäuscht werden.
Der nächste Schritt ist die Beurteilung dieser Fehlerhaftigkeit. Und dort wird es bei allgemeinen Chatbots eng.
Schenk (Quellenhinweis, siehe oben) nennt zwei zentrale Grenzen:
- Bei Chatbots mit allgemeinem Verwendungszweck ist wegen des breiten Anwendungsspektrums kein konkreter Gebrauch der Information identifizierbar.
- Es besteht regelmäßig keine berechtigte Erwartung, dass jede Antwort inhaltlich richtig ist oder dass der Anbieter die Trainingsdaten wie ein Universalexperte auf jede denkbare Fachrichtigkeit kontrolliert.
Das ist eine saubere Unterscheidung.
Ein allgemeiner Chatbot kann beim Schreiben einer Geburtstagskarte helfen, bei Python-Code, bei Steuerfragen, bei Fitnessplänen, bei Starkstromfragen oder bei der Frage ob Krümelmonster zu raten wäre, in seinem Lebenslauf noch einen Abschnitt “Extraterrestrisches” hinzufügen.
Der Hersteller kann nicht sinnvoll vorhersehen, in welchem konkreten physischen Kontext jede einzelne Antwort eingesetzt wird.
Bei einer spezialisierten KI-App sieht das anders aus.
Eine Insulin-App hat keinen offenen Weltzweck. Sie ist nicht „allgemeine Assistenz". Sie ist auf eine bestimmte Aufgabe ausgerichtet: aus medizinischen Ausgangsdaten eine Dosierungsempfehlung abzuleiten. Genau deshalb kann dort ein konkreter Gebrauch identifiziert werden. Und genau deshalb kann auch eine höhere Erwartung an Datenqualität, Testtiefe, Zweckbegrenzung, Fehlertoleranz und Instruktion bestehen.
Die saubere Linie lautet daher:
| FALL | EINORDNUNG |
|---|---|
| Allgemeiner Chatbot | Softwareprodukt möglich, Produkthaftung für Falschinformationen aber regelmäßig begrenzt durch fehlenden konkreten Gebrauch und fehlende berechtigte Richtigkeitserwartung |
| Spezialisierter KI-Chatbot oder KI-App | Produkthaftung kann ernsthaft in Betracht kommen, wenn Zweck, Nutzerkreis und physische Umsetzung erkennbar sind |
| Medizinische Dosierungs-App | Paradefall für die Frage, ob eine fehlerhafte Softwareausführung zu einem Körper- oder Gesundheitsschaden geführt hat |
Damit ist auch klar: Die Richtlinie macht nicht jede Halluzination haftungsrechtlich relevant. Sie interessiert sich nicht für jeden Unsinn, den ein allgemeiner Chatbot in die Welt rotzt wie ein besoffener Papagei mit eingebauter Funkantenne.
Sie interessiert sich aber sehr wohl für Software, die in einem konkreten sicherheitsrelevanten Kontext bestimmungsgemäß Entscheidungen vorbereitet, berechnet oder anstößt.
DER RELEASE IST NICHT MEHR DAS ENDE DER GESCHICHTE
Bis hierhin ist nur die erste Schwelle erreicht: Software kann ein „Produkt" sein. Für KI-Anwendungen ist damit aber noch nichts entschieden.
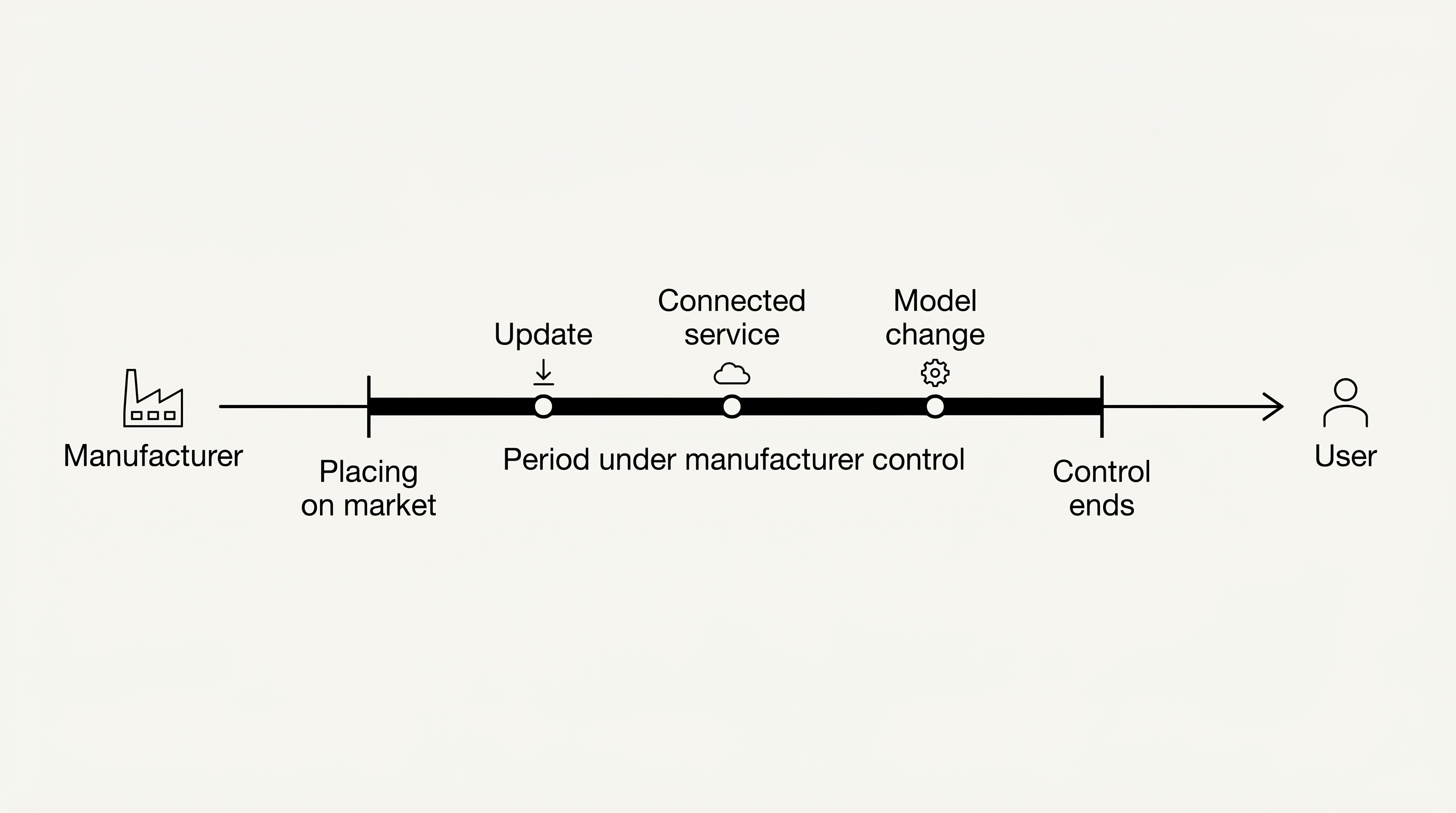
Der entscheidende Teil beginnt danach. Die Richtlinie behandelt digitale Produkte nicht mehr so, als würden sie nach dem Inverkehrbringen in rechtlicher Tiefkühlstarre liegen. Gerade Software bleibt häufig unter Einfluss des Herstellers, etwa durch Updates und Upgrades, verbundene Dienste, Cloud-Komponenten, Modelländerungen oder fortlaufendes Lernen.
Das ist der Bruch mit der klassischen Fixpunktlogik.
Im traditionellen Produkthaftungsrecht war das Inverkehrbringen der Ankerpunkt: Das Produkt verlässt den Hersteller, und die rechtliche Bewertung fokussiert diesen Zeitpunkt. Bei moderner Software greift das zu kurz. Ein KI-System kann sich nach dem Release verändern. Es kann vom Hersteller verändert werden. Es kann durch ausbleibende Updates unsicher werden. Und es kann von verbundenen Diensten abhängen, die im Hintergrund funktional mittragen, was das Produkt verspricht.
Die Richtlinie reagiert darauf mit einem Kontrollgedanken.
Art. 7 Abs. 2 lit. e RL (EU) 2024/2853 verlangt bei der Fehlerbeurteilung, den Zeitpunkt zu berücksichtigen,
„zu dem das Produkt in Verkehr gebracht oder in Betrieb genommen wurde, oder, wenn der Hersteller nach diesem Zeitpunkt die Kontrolle über das Produkt behält, des Zeitpunktes, in dem das Produkt die Kontrolle des Herstellers verlassen hat".
Das ist die Scharniernorm: Nicht nur der Release zählt, sondern der Zeitraum, in dem der Hersteller noch Kontrolle über das Produkt behält.
Und „Kontrolle" ist kein unbestimmter Rechtsbegriff, der an den Rändern von den vielen Auslegungen schon ausgefranst ist. Nein, Art. 4 Nr. 5 RL (EU) 2024/2853 definiert sie ausdrücklich. Kontrolle liegt unter anderem vor, wenn der Hersteller die Integration, Verbindung oder Bereitstellung einer Komponente genehmigt oder ihr zustimmt, einschließlich Software-Updates oder Upgrades. Kontrolle liegt außerdem vor, wenn der Hersteller in der Lage ist, Software-Updates oder Upgrades selbst bereitzustellen oder durch Dritte bereitstellen zu lassen.
Für KI-Produkte ist das praktisch entscheidend: Updatefähigkeit ist nicht nur Komfort, sondern ein haftungsrechtliches Kontrollmerkmal.
- Wer ein Modell nachträglich aktualisieren kann, behält Kontrolle.
- Wer Updates ausrollen kann, behält Kontrolle.
- Wer ein Cloud-Modell austauscht, behält Kontrolle.
- Wer einen verbundenen Dienst als Teil des Produkts präsentiert, bewegt sich nicht im haftungsfreien Raum.
Die berechtigte Verkehrserwartung bezieht sich nicht mehr nur auf das Inverkehrbringen, sondern auf den gesamten Zeitraum, in dem das Produkt unter Kontrolle des Herstellers steht. Die bloße Updatefähigkeit reicht nach Art. 4 Nr. 5 lit. b aus, um Kontrolle zu begründen.
LERNEN NACH DEM RELEASE

Für KI-Systeme kommt ein zweiter, haftungsrelevanter Faktor hinzu: Lernfähigkeit.
Art. 7 Abs. 2 lit. c RL (EU) 2024/2853 verlangt ausdrücklich, die Auswirkungen der Fähigkeit eines Produkts zu berücksichtigen,
„nach seinem Inverkehrbringen oder seiner Inbetriebnahme weiter zu lernen oder neue Funktionen zu erwerben".
Erwägungsgrund 32 präzisiert die Erwartung dahinter: Software und Algorithmen müssen so konzipiert sein, dass gefährliches Produktverhalten verhindert wird. Wer ein Produkt entwickelt, das unerwartetes Verhalten entwickeln kann, soll deshalb auch für schadensverursachendes Verhalten weiterhin einstehen.
Dass lernfähige Produkte in der Nutzung unerwartetes Verhalten zeigen können, führt damit weder zu einer pauschalen Haftungsbefreiung noch zu einem faktischen Verbot. Es verschiebt den Maßstab: Lern- und Funktionszuwächse gehören in die Sicherheitsbewertung, und das System muss so ausgelegt sein, dass gefährliche Entwicklungen verhindert oder jedenfalls zuverlässig erkannt und begrenzt werden.
Der Punkt ist simpel: Die Richtlinie sagt nicht „KI ist böse". Sie sagt: Wenn dein System lernen oder neue Funktionen erwerben kann, ist genau diese Dynamik Teil des Risikos. Der Hersteller kann sich nicht darauf zurückziehen, das Modell sei „nach dem Release halt komisch geworden".
„Komisch geworden" ist kein Entlastungsgrund. Das ist höchstens eine schlechte Incident-Response-Überschrift.
Für unsere Insulin-App heißt das: Werden Modell, Dosierungslogik oder Parameter nachträglich verändert, lernt das System aus Nutzungsdaten oder wird ein Update ausgerollt, verändert sich die Risikolage. Dann muss beweisfähig nachvollziehbar sein, was sich geändert hat, wann es sich geändert hat und ob die Änderung sicherheitsrelevant war.
UPDATES UND FEHLENDE UPDATES
Jetzt wird es noch unangenehmer.
Art. 11 Abs. 1 lit. c RL (EU) 2024/2853 enthält zwar weiterhin einen klassischen Entlastungsgrund: Der Wirtschaftsakteur haftet nicht, wenn er beweist, dass die Fehlerhaftigkeit zum Zeitpunkt des Inverkehrbringens oder der Inbetriebnahme wahrscheinlich noch nicht bestanden hat oder erst danach entstanden ist.
Klingt beruhigend.
Ist es aber nur zur Hälfte.
Denn Art. 11 Abs. 2 begrenzt diesen Entlastungsgrund. Ein Wirtschaftsakteur wird nicht von der Haftung befreit, wenn die Fehlerhaftigkeit auf Umständen beruht, die der Kontrolle des Herstellers unterliegen, insbesondere:
- einem verbundenen Dienst,
- Software, einschließlich Software-Updates oder Upgrades,
- dem Fehlen von Software-Updates oder Upgrades, die zur Aufrechterhaltung der Sicherheit erforderlich sind,
- einer wesentlichen Änderung des Produkts.
Praktisch ist das die Achillesferse moderner GenAI-Lieferketten. Wer ein Basismodell übernimmt – etwa ein europäisches Open-Source-Modell – es mit eigenen Daten feintunt, mit Systemprompts, Guardrails und Tooling anreichert und als API anbietet, kann die Haftung nicht an den Basismodell-Anbieter durchreichen. Eine wesentliche Veränderung im Sinne der Richtlinie macht den Modifizierenden zum Hersteller des veränderten Produkts.
Das Open-Source-Schild des Vorlieferanten ist dann kein Schutzdach, sondern eine Fußnote in der eigenen Komponentenliste.
Haftungsrelevant ist also nicht nur ein fehlerhaftes Update.
Auch ein unterlassenes, sicherheitsrelevantes Update kann zum Problem werden.
Erwägungsgrund 51 stellt zwar klar, dass die Richtlinie keine ausdrückliche Verpflichtung zur Bereitstellung von Updates oder Upgrades normiert. Praktisch bleibt dem Hersteller aber, um einem Schadensersatzverlangen zu entgehen, oft nichts anderes übrig, als sicherheitsrelevante Updates bereitzustellen.
Wird eine Sicherheitslücke bekannt und kann der Hersteller sie durch ein Update schließen, ist „Wir hatten keine Lust mehr auf Support" keine tragfähige Verteidigung, sondern eher ein forensischer Abschiedsbrief.
Für KI-Anwendungen folgt daraus:
- Sicherheitslücken im Modellbetrieb müssen beobachtet werden.
- Abhängigkeiten müssen gepflegt werden.
- API-Änderungen müssen kontrolliert werden.
- Modellupdates müssen getestet werden.
- Rollbacks müssen möglich sein.
- Security-Patches müssen dokumentiert werden.
- Das Ende des Supports muss haftungsrechtlich mitgedacht werden.
Das ist keine Compliance-Deko. Das ist Lebenszyklusverantwortung.
VERBUNDENE DIENSTE: WENN DIE APP NICHT ALLEIN ARBEITET
Moderne KI-Anwendungen stehen selten für sich.
Sie hängen an Cloud-Inferenz, externen Modellen, Datenbanken, Embedding-Diensten, Authentifizierungs- und Monitoring-Systemen, Vector Stores, Sensoren oder Drittanbieter-APIs. Produkthaftungsrechtlich wird das nicht pauschal gleich behandelt. Die Richtlinie unterscheidet vielmehr: Für funktionswesentliche digitale Dienste gibt es die eigene Kategorie des verbundenen Dienstes.
Art. 4 Nr. 3 RL (EU) 2024/2853 definiert den verbundenen Dienst als digitalen Dienst,
„der so in ein Produkt integriert oder so mit ihm verbunden ist, dass das Produkt ohne ihn eine oder mehrere seiner Funktionen nicht ausführen könnte".
Art. 4 Nr. 4 qualifiziert den verbundenen Dienst als Komponente.
Das ist dogmatisch klar genug, um praktisch unbequem zu werden.
Bei vernetzten Produkten hängt die Funktions- und Sicherheitsleistung nicht mehr nur von der eigenen Konstruktion ab, sondern auch von digitalen Diensten. Fehlerhafte Daten, Funktionsstörungen eines Dienstes oder ihr Zusammenwirken können schadensursächlich sein. Verbundene Dienste können für die Sicherheit des Produkts damit ebenso grundlegend sein wie physische oder digitale Komponenten.
Gleichzeitig setzt die Richtlinie Grenzen.
Nicht jeder irgendwie angebundene Dienst ist automatisch ein verbundener Dienst. Maßgeblich ist, ob das Produkt ohne ihn eine oder mehrere Funktionen nicht ausführen könnte, und ob der Dienst unter Kontrolle des Herstellers integriert oder verbunden wurde.
Erwägungsgrund 18 präzisiert diese Kontrollschwelle: Es genügt nicht, dass der Hersteller eine technische Integrationsmöglichkeit schafft, bestimmte Marken empfiehlt oder potenzielle Dienste nicht verbietet. Anders liegt es, wenn der Hersteller die Integration oder Bereitstellung genehmigt, ihr zustimmt oder den Dienst als Teil des Produkts präsentiert.
Für unsere Insulin-App heißt das:
Wenn die App nur mit einem bestimmten Cloud-Inferenzdienst funktioniert, der die Dosierung berechnet, ist dieser Dienst keine austauschbare Infrastruktur. Er ist funktional erforderlich. Und wenn der Hersteller ihn integriert, bereitstellt oder als Teil des Produkts präsentiert, greift die Kontrolllogik.
Dann trägt die spätere Ausrede
„Das war nicht unsere App. Das war der Dienst dahinter."
nicht (mehr).
WARUM DAS EIN ARCHITEKTURTHEMA IST
Damit ist der entscheidende Übergang erreicht.
Die Richtlinie zwingt Hersteller nicht nur, Software als Produkt ernst zu nehmen. Sie zwingt sie auch, den Betrieb als Teil der haftungsrechtlichen Realität genauso ernst zu nehmen.
Für KI-Systeme heißt das: Der rechtlich relevante Zustand des Produkts liegt nicht in einem einzelnen Release-Artefakt, sondern in einer Abfolge von Zuständen.
- Welche Modellversion war produktiv?
- Welcher Datenstand war maßgeblich?
- Welche API-Version wurde genutzt?
- Welche Updates wurden wann ausgerollt?
- Welche Sicherheitslücken waren bekannt?
- Welche Patches standen bereit oder wurden eingespielt?
- Welche verbundenen Dienste waren aktiv?
- Welche Änderungen lagen unter der Kontrolle des Herstellers?
Genau hier beginnt das Architekturproblem. Oder um es so zu formulieren, wie es ein Tschaka-Tschaka-Coach sagen würden (deren natürliches Habitat LinkedIn ist): Die ArchitekturHERAUSFORDERUNG. Nicht das Problem, Herausforderung. Schön merken, Krümelmonster fragt dich nachher ab. Und wenn du das nicht weißt, … (einfach mal Predator gucken).
Wer diese Fragen (Modellversion, Datenstand, API-Version, etc.) im laufenden Betrieb nicht beantworten kann, hat später nicht nur ein Erkenntnisproblem, sondern vor allem ein Beweisproblem.
Dieses Beweisproblem ist kein internes Risiko mit Ampelfarbe Gelb, sondern der Einstieg in die nächste Eskalationsstufe (also Farbe rot): Offenlegungspflichten, Vermutungen und prozessuale Nachteile.
Der Release ist damit nicht mehr das Ende der Geschichte.
Er ist der erste Eintrag in einem Haftungsprotokoll, das über den gesamten kontrollierten Lebenszyklus fortgeschrieben wird.
WENN DIE BLACK BOX SCHWEIGT, GREIFT DAS PROZESSRECHT
Bis hierhin klingt alles noch wie Produktrecht mit digitalem Anstrich.
Software ist Produkt.
Der Release ist nicht mehr das Ende.
Kontrolle, Updates und verbundene Dienste zählen.
Aber der eigentliche Hebel liegt im Prozess.
Denn ein Haftungsregime ist nur so scharf wie seine Beweisregeln. Wenn eine Patientin zwar geschädigt wurde, aber niemals beweisen kann, was im KI-System passiert ist, bleibt das schönste Haftungsrecht ein dekorativer Papiertiger. Mit Schleifchen. Für die juristische Fensterbank.
Genau dort setzt die Richtlinie an.
Art. 10 Abs. 1 RL (EU) 2024/2853 hält zunächst am klassischen Grundsatz fest:
Der Kläger hat die Fehlerhaftigkeit des Produkts, den erlittenen Schaden und den ursächlichen Zusammenhang zwischen dieser Fehlerhaftigkeit und diesem Schaden zu beweisen.
Das klingt altbekannt.
Aber danach wird es unangenehm. Also noch unangenehmer als vorher.
Aber mal ganz kurz Spaß und Krümelmonster beiseite.
Würdest du da nicht auch Ansprüche geltend machen wollen? Gegen eine Software, die als sicher und zuverlässig verkauft wurde, obwohl sie offenbar von einem wochenendzertifizierten Vibe-Coder, früher einer der besten Kirmesboxer, zwischen zwei Paletten Schnaps mit Lovable oder irgendeinem anderen KI-Tool zusammengeklöppelt wurde und am Ende dein komplettes PayPal-Konto leergeräumt hat, damit das Geld beim berühmten Prinzen aus Nigeria landet?
Oder in Wanne-Eickel. Klingt nur nicht so gut.
Ich wäre froh, wenn ich Kirmesboxer-Kalle danach verklagen kann, sofern der nicht schon seine ganze Kohle für Korrekturiterationsschleifen bei Lovable verballert hat (und den Rest für die dritte Palette Schnaps).
Art. 9 RL (EU) 2024/2853 verpflichtet den Beklagten unter bestimmten Voraussetzungen zur Offenlegung relevanter Beweismittel, wenn der Kläger Tatsachen vorgetragen und Beweismittel vorgelegt hat, welche die Plausibilität des Anspruchs ausreichend stützen. Die Offenlegung ist auf das erforderliche und verhältnismäßige Maß begrenzt; Geschäftsgeheimnisse werden geschützt, aber nicht absolut. Das Gericht kann sogar anordnen, dass Beweismittel in leicht zugänglicher und leicht verständlicher Form vorgelegt werden.
Das ist bei KI-Systemen kein Nebenschauplatz.
Denn relevante Beweismittel können genau das sein, was in vielen Projekten irgendwo zwischen DevOps, Data Science, Security, Product Owner und „Müsste mal jemand dokumentieren" verendet:
- Modellversionen
- Trainings- und Testdatenstände
- Datalineage
- Update-Historien
- Test- und Validierungsprotokolle
- Monitoring-Daten
- Logs
- Incident Reports
- Änderungen an Prompts, Policies oder Systemparametern
- Dokumentation angebundener Dienste und Komponenten
Geschäftsgeheimnisse sind dabei kein Freifahrtschein. Art. 9 Abs. 4 und 5 verlangt zwar Schutz vertraulicher Informationen und Geschäftsgeheimnisse. Aber der Schutz dient der Vertraulichkeit im Verfahren, nicht der vollständigen Flucht vor Offenlegung. Anders gesagt: „Das ist unser Geschäftsgeheimnis" ist ein Schutzschild. Kein Unsichtbarkeitsumhang.
Der zweite Hebel sitzt in Art. 10.
Die Fehlerhaftigkeit wird unter anderem vermutet, wenn der Beklagte relevante Beweismittel nach Art. 9 Abs. 1 nicht offenlegt, wenn verbindliche Produktsicherheitsanforderungen verletzt wurden oder wenn der Schaden durch eine offensichtliche Funktionsstörung bei vernünftigerweise vorhersehbarem Gebrauch verursacht wurde.
Für Hersteller ist das prozessual giftig.
Wer nicht dokumentiert, kann später nicht offenlegen.
Wer nicht offenlegt, riskiert eine Fehlervermutung.
Wer eine Fehlervermutung kassiert, diskutiert nicht mehr aus der Position technischer Souveränität, sondern aus der Position eines Mannes, der mit Benzinkanister neben der brennenden Scheune steht und sagt, das sei alles sehr komplex.
Noch schärfer ist Art. 10 Abs. 4.
Ein nationales Gericht geht von der Fehlerhaftigkeit des Produkts, dem ursächlichen Zusammenhang oder beidem aus, wenn es für den Kläger trotz Offenlegung insbesondere wegen technischer oder wissenschaftlicher Komplexität übermäßig schwierig ist, Fehlerhaftigkeit oder Kausalität zu beweisen, und der Kläger nur wahrscheinlich machen kann, dass das Produkt fehlerhaft war oder der Fehler den Schaden verursacht hat.
Erwägungsgrund 48 nennt als Faktoren ausdrücklich die Komplexität des Produkts, die Komplexität der verwendeten Technologie, etwa maschinelles Lernen, die Komplexität der zu analysierenden Informationen und Daten sowie die Komplexität des ursächlichen Zusammenhangs. Der Kläger soll bei einer Klage zu einem KI-System gerade nicht verpflichtet sein, die spezifischen Merkmale des KI-Systems oder deren Bedeutung für die Kausalität im Einzelnen zu erklären, damit das Gericht übermäßige Schwierigkeiten annehmen kann.
Das ist der Moment, in dem die Black Box die Seite wechselt.
Früher konnte technische Komplexität faktisch dem Kläger schaden: Er sah den Schaden, aber nicht das System. Er konnte Symptome beschreiben, aber nicht die innere Mechanik beweisen.
Die Richtlinie dreht diese Lage nicht vollständig um. Sie schafft keine automatische Herstellerhaftung für jedes digitale Desaster. Aber sie erkennt die Informationsasymmetrie an. Hersteller wissen mehr über ihre Systeme als Geschädigte. Deshalb sollen Beweismittel zugänglich werden, und deshalb können Vermutungen greifen.
Für unsere Insulin-App heißt das:
Wenn die Patientin darlegt, dass nach Nutzung der App eine falsche Dosierungsempfehlung zu einem Körperschaden geführt hat, wird es für den Hersteller nicht reichen, auf die Komplexität des KI-Systems zu zeigen. Dann werden die Fragen konkret:
- Welche Version war aktiv?
- Welche Eingabedaten wurden verarbeitet?
- Welche Dosierungslogik oder welches Modell wurde genutzt?
- Gab es bekannte Fehler?
- Gab es ein Update?
- Gab es ein fehlendes Sicherheitsupdate?
- Welche Logs existieren?
- Welche Tests wurden durchgeführt?
- War der Fehler reproduzierbar?
- Welche verbundenen Dienste waren beteiligt?
Wenn darauf nur Schulterzucken kommt, ist das kein technisches Detail mehr. Es ist ein Prozessproblem.
Und genau daraus folgt der eigentliche Architekturpunkt.
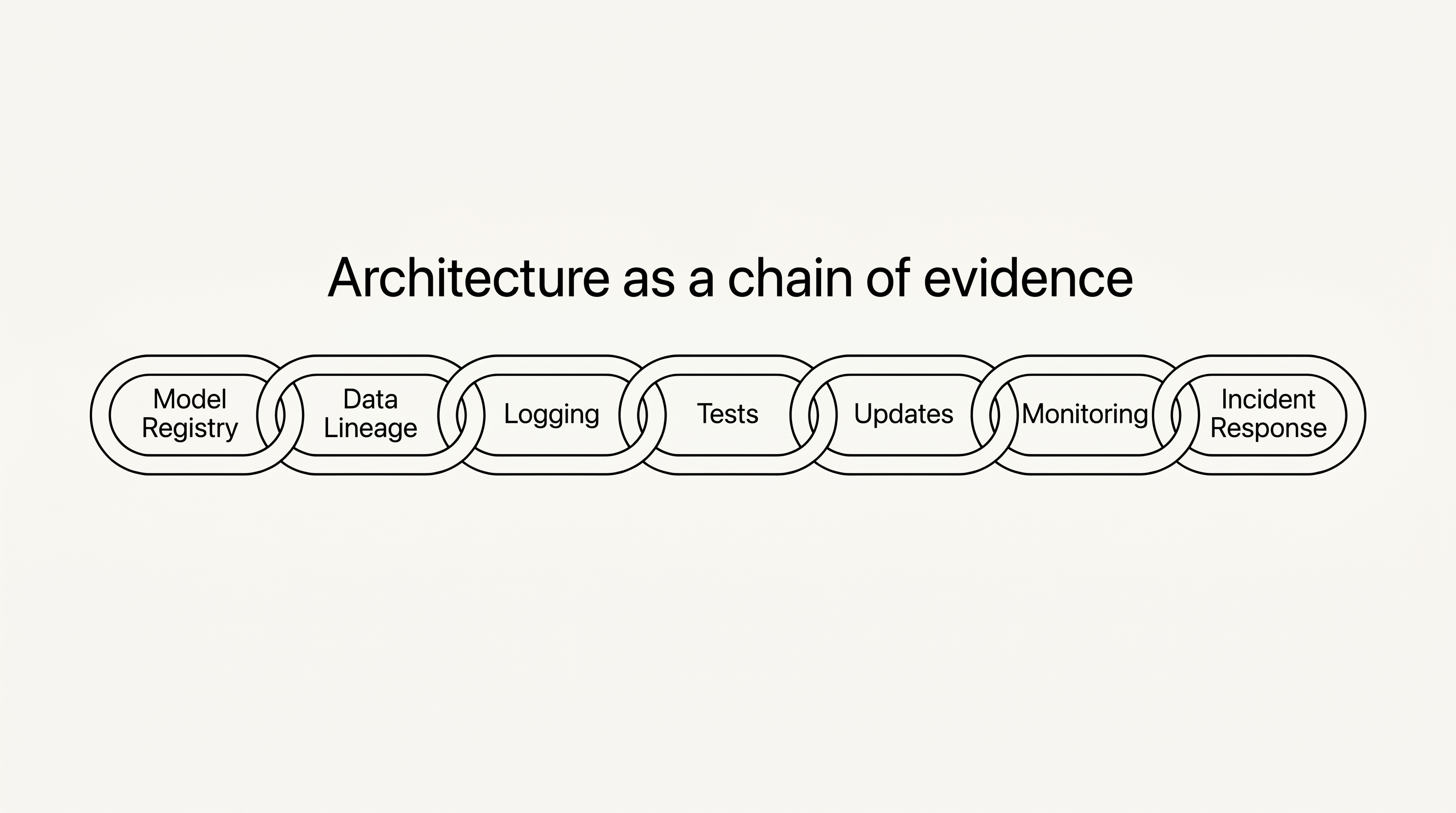
ARCHITEKTUR IST DIE NEUE BEWEISKETTE
Die Antwort auf diese Richtlinie lautet nicht: mehr Doku.
Sie lautet auch nicht: „Legal soll mal einen Disclaimer schreiben."
Disclaimer sind die Duftbäumchen der Compliance. Sie riechen kurz nach Kontrolle, ändern aber nichts am Unfall.
Wenn die neue Produkthaftung Software, KI, Updates, verbundene Dienste und technische Komplexität ernst nimmt, dann muss die technische Organisation beweisfähig werden.
Das heißt nicht, dass jedes KI-System zu einer bürokratischen Kathedrale aus Formularen, Prozessdiagrammen und toten SharePoint-Ordnern werden muss. Es heißt aber: Wer sicherheitsrelevante KI baut oder betreibt, muss später rekonstruieren können, was sein System getan hat und warum.
Bei unserer Insulin-App reicht deshalb nicht:
Wir hatten ein Modell.
Die relevante Frage lautet:
Welches Modell, mit welchen Daten, in welcher Version, mit welchem Update-Stand, unter welcher Konfiguration, bei welchem Input, mit welchem Output, unter welchem Monitoring und mit welcher Freigabe?
Das ist Architektur. Nicht Folklore.
Für Hersteller, Entwickler und CTOs ergeben sich daraus konkrete technische Bausteine:
| BAUSTEIN | WARUM ER HAFTUNGSRELEVANT WIRD |
|---|---|
| Model Registry | Nachweis, welche Modellversion wann produktiv war |
| Dataset-Versionierung | Rekonstruktion, welche Datenstände Training, Fine-Tuning oder Tests geprägt haben |
| Datalineage | Nachvollziehbarkeit von Herkunft, Verarbeitung und Veränderung relevanter Daten |
| Logging | Nachweis von Eingaben, Outputs, Fehlern und Systemzuständen |
| Update- und Patch-Historie | Beleg, welche Änderungen wann ausgerollt oder unterlassen wurden |
| Monitoring und Drift Detection | Früherkennung von Abweichungen im Betrieb |
| Testprotokolle | Nachweis von Validierung, Robustheit, Grenzfällen und Regressionen |
| Incident Response | strukturierter Umgang mit Fehlern, Schäden und Rückverfolgung |
| Dokumentation verbundener Dienste | Klärung, welche externen Dienste funktional relevant und kontrolliert waren |
| Freigabe- und Verantwortlichkeitsmodell | Nachweis, wer welche Betriebsentscheidung getroffen hat |
Das klingt trocken. Ist es auch. Aber trocken ist besser als brennend.
Diese Artefakte sind nicht nur für Audits relevant. Sie werden im Streitfall zu Beweismitteln. Genau hier treffen Produkthaftungsrecht und KI-Architektur aufeinander.
Und hier liegt auch der Anschluss an den EU AI Act.
Die Produkthaftungsrichtlinie ersetzt den EU AI Act nicht. Sie macht etwas anderes.
Der EU AI Act fragt vor allem: Darf dieses KI-System so entwickelt, in Verkehr gebracht, betrieben und überwacht werden? Bei Hochrisiko-KI-Systemen geht es etwa um Risikomanagement, Daten- und Daten-Governance, technische Dokumentation, Aufzeichnungspflichten, Transparenz, menschliche Aufsicht, Genauigkeit, Robustheit und Cybersicherheit.
Die Produkthaftungsrichtlinie fragt nach dem Schaden:
War das Produkt fehlerhaft, ist dadurch ein ersatzfähiger Schaden entstanden, und wer kann was beweisen?
Das sind unterschiedliche Perspektiven. Aber sie greifen ineinander wie zwei Zahnräder, die man besser nicht mit der Hand anhält.
| REGELWERK | PRIMÄRE FRAGE | PRAKTISCHE RELEVANZ |
|---|---|---|
| EU AI Act | Ist das KI-System konform entwickelt und betrieben? | Governance, Dokumentation, Risikomanagement, Logging, Post-Market-Monitoring |
| Produkthaftungsrichtlinie | Wer haftet nach einem Schaden durch ein fehlerhaftes Produkt? | Fehler, Schaden, Kausalität, Offenlegung, Vermutungen |
| DSGVO | Wurden personenbezogene Daten rechtmäßig verarbeitet? | Datenschutz, Betroffenenrechte, Art. 82 DSGVO |
| CRA / Produktsicherheitsrecht | Ist das Produkt sicher und cyberresilient? | Security by Design, Updates, Schwachstellenmanagement |
Der praktische Effekt ist simpel:
Was im AI-Act-Kontext wie Compliance-Dokumentation aussieht, kann im Produkthaftungsprozess zur Verteidigungslinie werden.
Mehr noch: Wer den AI Act ernst nimmt – Logging, Risikomanagement, technische Dokumentation, Post-Market-Monitoring – produziert genau jene Beweismittel, deren Fehlen Art. 10 Abs. 2 lit. a RL (EU) 2024/2853 in eine Fehlervermutung kippen lässt. Wer offenlegen kann, ist nicht darauf angewiesen, dass das Gericht von Vermutungen keinen Gebrauch macht.
Architektur ist damit nicht nur Beweiskette nach dem Schaden. Sie ist der Pre-emptive Strike vor dem Prozess: Wer sauber dokumentiert, schließt der Klägerseite die prozessuale Tür, bevor sie aufgeht.
Wer Risikomanagement nur als Policy betreibt, hat im Prozess wenig gewonnen. Wer Logging nur einschaltet, aber nicht auswerten oder erklären kann, hat ein digitales Aquarium gebaut: Man sieht Bewegung, versteht aber nichts. Wer Modellversionen nicht sauber verwaltet, kann später nicht beweisen, welches System überhaupt gehandelt hat.
Deshalb ist „Compliance by Design" hier kein hübscher Beratungsslogan.
Es bedeutet: Die Architektur muss von Anfang an so gebaut sein, dass sie Sicherheit nicht nur behauptet, sondern nachweist.
Für eine KI-gestützte Insulin-App hieße das zum Beispiel:
- Jede produktive Modellversion ist eindeutig identifizierbar.
- Jede Dosierungsempfehlung ist mit Input, Modellversion, Konfiguration und Zeitstempel verknüpft.
- Kritische Änderungen durchlaufen dokumentierte Tests.
- Sicherheitsrelevante Updates werden versioniert, geprüft und nachvollziehbar ausgerollt.
- Externe Dienste werden nicht nur integriert, sondern vertraglich, technisch und organisatorisch kontrolliert.
- Fehlerfälle lösen Incident-Prozesse aus.
- Die Logs sind nicht nur vorhanden, sondern auswertbar.
- Die Dokumentation ist so geschrieben, dass nicht nur der ursprüngliche Entwickler sie versteht, der inzwischen in Bali sitzt und handgemachten Kombucha fermentiert.
Der letzte Punkt ist weniger lustig, als er klingt.
Art. 9 Abs. 6 erlaubt dem Gericht, die Vorlage von Beweismitteln in einer leicht zugänglichen und leicht verständlichen Form zu verlangen, sofern das verhältnismäßig ist. Im Zweifel geht es nicht um eine kryptische Log-Halde, sondern um verwertbare Aufklärung.
Damit wird Architektur zur Übersetzungsleistung:
zwischen Modell und Gericht,
zwischen Runtime und Beweis,
zwischen MLOps und Haftung.
Wer das nicht baut, kann Glück haben.
Glück ist jedoch keine Governance-Strategie, zumindest keine, die ein Audit überlebt.
FAZIT: WER KI BAUT, BAUT EINE BEWEISKETTE
Die neue Produkthaftungsrichtlinie ist kein isoliertes juristisches Spielzeug. Sie ist Teil einer europäischen Digitalregulierung, die Software, KI, Daten, Cybersicherheit und Produktverantwortung enger verzahnt.
Der entscheidende Punkt ist nicht nur, dass Software nun ausdrücklich ein „Produkt" sein kann.
Entscheidend ist, was daraus folgt.
Bei KI-Systemen endet Verantwortung nicht mit dem Release. Sie wirkt fort, solange Hersteller Kontrolle behalten, etwa über Updates, verbundene Dienste, Modelländerungen, sicherheitsrelevante Patches oder lernende Funktionen.
Und wenn etwas schiefgeht, genügt es nicht, nachträglich auf die Komplexität des Systems zu verweisen. Komplexität ist kein Schutzschild. Nach Art. 9 und Art. 10 RL (EU) 2024/2853 kann sie vielmehr der Auslöser dafür sein, dass Offenlegungspflichten greifen und das Gericht mit Vermutungen sowie prozessualen Beweiserleichterungen arbeitet.
Das ist die eigentliche Zumutung der Reform.
Sie verlangt von Herstellern, Entwicklern und CTOs nicht nur sichere Produkte, sondern Systeme, deren Verhalten sich erklären, rekonstruieren und im Streitfall beweisfähig dokumentieren lässt.
Für Jurist:innen heißt das: Produkthaftung für KI lässt sich nicht mehr belastbar beraten, wenn man nicht versteht, wie Modelle deployed, versioniert, überwacht und aktualisiert werden.
Für Techniker:innen heißt das: Architekturentscheidungen sind nicht nur Fragen von Skalierung, Kosten und Performance. Sie entscheiden mit darüber, ob ein Unternehmen im Haftungsprozess substanziiert vortragen und sich verteidigen kann, oder ob es am Ende auf die eigenen Loglücken starrt.
Der EU AI Act fragt nach Konformität.
Die Produkthaftung fragt nach Verantwortung nach dem Schaden.
Die Architektur entscheidet, ob darauf eine Antwort möglich ist.
Wer KI baut, baut künftig nicht nur ein Produkt.
Er baut eine Beweiskette.
Und wer da Lücken hat, den holt das Krümelmonster.
QUELLEN
EU-RECHTSAKTE
- Richtlinie (EU) 2024/2853 des Europäischen Parlaments und des Rates vom 23. Oktober 2024 über die Haftung für fehlerhafte Produkte und zur Aufhebung der Richtlinie 85/374/EWG, ABl. L 2024/2853. URL: https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=CELEX:32024L2853
- Verordnung (EU) 2024/1689 (EU AI Act), ABl. L 2024/1689, in Kraft seit 01.08.2024. URL: https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=CELEX:32024R1689
NATIONALE UMSETZUNG
- BT-Drs. 21/4297 – Regierungsentwurf zur Umsetzung der Richtlinie (EU) 2024/2853 in deutsches Recht
LITERATUR
- Brenner, Raphael: „Software im Fokus der neuen Produkthaftungsrichtlinie", Recht Digital (RDi) 2024, 345–352
- Schenk, Ulrich: „Produkthaftung für falsche KI-Antworten nach der neuen Produkthaftungs-RL?", Legal Tech Zeitschrift (LTZ) 2025, 184–190