
Time to Pay Up, Vibe Coders: The EU Product Liability Directive 2024/2853
2026-04-26

Author: Jens Henneberg
As of: 2026-04-26 - 12:00
Picture this: you’re building an app that’s supposed to help with insulin dosing. Blood sugar in, dose out. The whole thing runs on AI. And underneath it, like on almost every AI gadget these days, sits the ritual little notice: “AI can make mistakes.” (Roughly the energy of those horror photos on cigarette packs.)
An experienced doctor uses the app. The values get keyed in by hand. The app does its sums. And somewhere in the code, an execution bug trips over its own shoelaces.
The recommendation is wrong. The doctor, frazzled as ever, follows it. The patient ends up in the ER.
What happened?
A software bug.
Manifested as bodily harm.
No screen is broken, no cable went up in flames. No: a patient had to be taken to the emergency room.
Cases exactly like this are why European product liability is being recalibrated. Directive (EU) 2024/2853 sweeps away the cosy assumption that, in liability terms, software and AI systems are nothing but immaterial fog with a user interface attached. Software is explicitly captured by the concept of a product. That holds even when it’s delivered as Software-as-a-Service or embedded as an AI system inside a larger application.
For manufacturers, developers and CTOs, this is no longer a fringe issue. Whoever places a product on the European market, makes it available, or puts it into service has to play by European liability rules. That’s the logic of the single market: same rules for everyone offering on this turf. Including providers from third countries. Including providers from the US. A corporate seat in Delaware is not a liability cloak of invisibility.
To stay dogmatically clean: Directive (EU) 2024/2853 is not a regulation. It does not — unlike the EU AI Act — apply directly in every Member State; it has to be transposed nationally. In Germany, that’s currently meant to happen via the government draft BT-Drs. 21/4297. The new rules are to apply to products placed on the market or put into service after 9 December 2026.
Hence the thesis of this article: the new product liability turns AI liability into an architectural problem. If you can’t reconstruct, with evidence, your model’s behaviour, your data lineage, your updates, your logs and your operational decisions, you don’t lose the audit first — you lose the liability suit.
The black box thus shifts from being the claimant’s evidentiary headache to being the manufacturer’s existential risk.
SOFTWARE IS A PRODUCT, NO MATTER WHERE IT COMES FROM OR HOW IT’S INTEGRATED
Article 4(1) of Directive (EU) 2024/2853 reads:
“Product means any movable item, even if integrated into, or interconnected with, another movable or immovable item; product shall also include electricity, digital manufacturing files, raw materials and software.”
With that, software has officially arrived inside the concept of a product. No more dogmatic groping in the dark, no more squabbling over whether a program is corporeal enough to trigger product liability. The legislator has simply pulled software into the regime of strict, no-fault product liability.
Recital 13 sharpens the point further: software can be tangible or intangible, placed on the market as a standalone product or later integrated as a component. Operating systems, firmware, computer programs, applications and AI systems are explicitly named. What does not matter is whether the software is installed locally, fetched over a communications network, comes from the cloud or is supplied as Software-as-a-Service.
The new directive ends the previous uncertainty about how to slot software into liability law and makes clear that the manner of provision or use is irrelevant.
For AI applications, that’s decisive. An AI-driven app running locally is software. An AI-driven app running as SaaS is also software. An AI system embedded inside a larger application doesn’t disappear from liability law just because there’s no screw head to grab.
Article 4(4) of Directive (EU) 2024/2853 defines a component as any tangible or intangible item, raw material or related service that is integrated into or interconnected with a product. Article 8(1)(b) provides for the liability of the manufacturer of a defective component, where that component was integrated into or interconnected with the product under the manufacturer’s control and caused the product to be defective.
On top of that: where embedded software is at fault, it isn’t only the end-product manufacturer who can be sued — the software manufacturer can be sued too.
For AI architecture, that’s the next stick of dynamite.
Because modern AI products almost never come as one monolithic lump of software. They’re a stack of models, APIs, cloud services, data pipelines, embeddings, front-ends, monitoring, update mechanisms — and very often third-party components. Under product liability law, the question is no longer just:
Is the product defective?
But also:
Which component caused the defect, who integrated it, and whose control was it under?
CODE IS NOT THE SAME AS SOFTWARE

This is where the first boundary line runs — and it’s more decisive than it looks at first glance.
Article 4(1) of Directive (EU) 2024/2853 explicitly captures software as a product. But it does not follow that every digital file, every text, every line of source code and every AI output is automatically a product in its own right.
Recital 13 draws the line: software can be a product; information cannot. That’s why the product liability rules are not meant to apply to the content of digital files — media files, e-books, or pure source code.
That sounds dry. But it’s the dogmatic fuse box for the entire argument.
Because “code” as an umbrella term is fuzzy. To classify it, you have to pull it apart. At least three levels need to be distinguished:
| LEVEL | CLASSIFICATION UNDER PRODUCT LIABILITY LAW |
|---|---|
| Pure source code | as information, in principle not a product |
| Machine-executable software | a product within the meaning of Art. 4(1) of Directive (EU) 2024/2853 |
| AI-generated output | not itself a product, but it can be the symptom of defectively executed software |
Brenner nails the consequence: source code is, first and foremost, information; as such, it falls outside the scope of the Product Liability Directive. The directive’s notion of software, by contrast, only covers machine-executable code. But once a developer hands source code over to a manufacturer, who turns it into a product and uses it there, that developer can still be on the hook as the manufacturer of a defective component for bugs in their source code (Brenner, Raphael. “Software im Fokus der neuen Produkthaftungsrichtlinie.” Recht Digital (RDi), 2024, 345–52).
So the line is clear: not every “code” is software in the liability sense. But software can arise out of source code. And the moment that software is executed as intended, and that very execution causes harm, we are squarely back in product liability.
We have to be careful here, and draw the line cleanly!
If an AI gives a faulty answer — say, by claiming that Cookie Monster from Sesame Street is in truth a man-eating alien — then that utterance is, first of all, just information. Wrong information, sure. Or maybe I just only ever got the kid-friendly cut as a child.
With AI answers, the information is not the product. Very important:
Information stays information.
If the AI malfunctions, it may spit out a wrong answer. In which case the defect lies with the software.
So the information itself is not the product — to say it again — but: a piece of information that turns out to be wrong lets you infer that the system, i.e. the product, might itself be defective.
This fine-grained distinction heads off two reasoning errors.
First: not every piece of wrong information that drops out of a digital system can be muscled into product liability. Otherwise every dodgy health tip, every blog post stuffed with dangerous half-knowledge and every revelation about Cookie Monster’s secret alien identity would suddenly count as a product defect.
Dogmatically that’s nonsense. In practice it would be madness.
Second: the reverse excuse — “It was only information” — doesn’t fly either, if that information is precisely the result of faulty software execution and is meant, by design, to be the basis for a physical action.
In short:
The wrong output is not the product. But it can show that the product worked badly.
WHAT ABOUT OUR APP?
In the insulin example, that distinction bites.
The app is not a digital pamphlet that simply hands off a ready-made health tip. It takes specific blood sugar values, processes them, and out of that calculates a new dosage recommendation.
If that recommendation is wrong because of an execution bug, the centre of gravity for liability is no longer the information as such, but the execution of the software product that produced the information in the first place.
That’s exactly how Schenk argues, using a blood-sugar app as the example: after manual input, the app miscalculates an insulin dose. It would, he says, be unfair to slam the door on product liability from the outset by pointing out that the harm was “only” triggered by a piece of bad information. And because AI systems are merely a sub-species of software, this classification shouldn’t depend on whether the dose was determined by AI or by deterministic program logic (Schenk, Ulrich. “Produkthaftung für falsche KI-Antworten nach der neuen Produkthaftungs-RL?” Legal Tech Zeitschrift (LTZ), 2025, 184–90). And sure — as ever in legal scholarship, you can find dissenting voices. But I see this exactly the way my colleague Schenk does.
The patient isn’t protected because AI is somehow inherently “more dangerous” than classical software. What matters is that, in a safety-critical context, software produces a concrete calculation that’s intended to be acted on in the physical world.
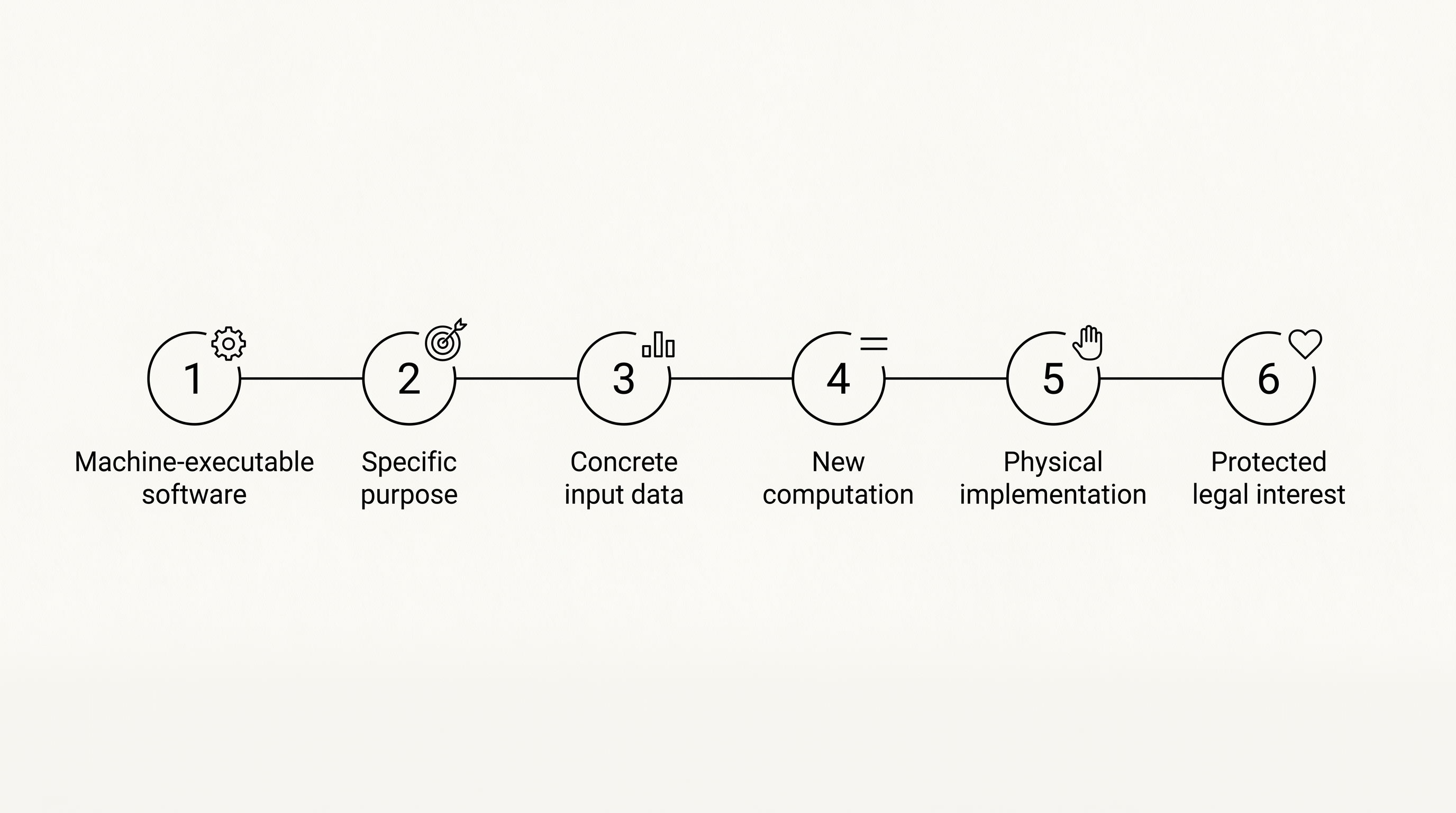
In the insulin app, several elements line up:
- Machine-executable software: the app is software within the meaning of Article 4(1).
- Specific purpose: it’s there to help dose insulin.
- Concrete input data: the blood sugar values come from the patient’s own sphere.
- A new calculation: the dose recommendation only comes into being through execution.
- Physical implementation: the recommendation is meant to be carried out medically.
- Protected legal interest: what’s at stake is bodily integrity, i.e. Article 6(1)(a) of Directive (EU) 2024/2853.
The app is therefore not “an old herbalist priest, gone digital”, and not a mere carrier of information. It’s a software product that turns patient data into a dosage recommendation. If the way that recommendation is produced is faulty, we’re not in some weightless world of information liability — we’re in product liability for software that ran badly.
And exactly that is why the tiny disclaimer doesn’t save you (the one you can’t escape these days; the only place it hasn’t surfaced yet is on yoghurt pots):
“AI can make mistakes.”
Warnings can play a role in assessing defectiveness. But Recital 31 makes clear that warnings or other information are not enough to make a product safe if it is otherwise defective.
You don’t dodge liability by listing every conceivable risk in fine print.
WHAT WOULD THIS LOOK LIKE FOR CHATBOTS?

For general-purpose AI chatbots, the picture changes.
Not because chatbots aren’t software. Of course they are. With offerings like these, the back-end that generates the answer and the front-end that takes the prompt and shows the response form a single product. Splitting them artificially would cut against the spirit of Recital 13, which is precisely meant to capture software regardless of whether it runs locally or on the server side.
But that doesn’t yet decide the liability question.
Because liability needs a defect.
Under Article 7(1) of the new Product Liability Directive (Directive (EU) 2024/2853), a product is to be regarded as defective when it does not provide the safety that a person is entitled to expect, or that is required by law. The directive uses an objective yardstick of the safety the public at large may legitimately expect. To establish that safety expectation, Article 7(2) forces an overall view of all the relevant circumstances. Among them: the product’s presentation, the effects of its ability to keep on learning after release, and — crucially — its “reasonably foreseeable use”.
So an AI system is not legally defective just because it puts out factually wrong information. Liability requires that the wrong information stems from a defective execution of the AI (e.g. through a design, manufacturing or instruction defect) and that, in foreseeable use, this disappoints those objective safety expectations.
The next step is the assessment of that defectiveness. And that’s where things get tight for general chatbots.
Schenk (citation above) names two key limits:
- With chatbots designed for general use, you can’t pin down a specific use of any given piece of information, because the application range is so wide.
- There is, as a rule, no legitimate expectation that every answer is factually correct, or that the provider polices the training data like some omniscient subject-matter expert across every conceivable field.
That’s a clean distinction.
A general chatbot can help you write a birthday card, debug Python, work through a tax question, plan a workout, ask about high-voltage wiring — or settle the question whether Cookie Monster ought to add an “Extraterrestrial” section to his CV.
The provider cannot meaningfully foresee in which concrete, physical context any single answer is going to be used.
With a specialised AI app, things look different.
An insulin app does not have an open-world purpose. It isn’t “general assistance”. It is built for a specific task: turning medical input data into a dosage recommendation. That’s why a concrete use can be pinned down. And that’s why, there, you can fairly demand more in terms of data quality, depth of testing, scope limitation, fault tolerance and instructions for use.
So the clean line reads:
| CASE | CLASSIFICATION |
|---|---|
| General-purpose chatbot | Software product possible, but product liability for false information is regularly limited by the lack of a concrete use and the lack of any legitimate expectation that every answer is correct |
| Specialised AI chatbot or AI app | Product liability can come into play in earnest where purpose, user group and physical implementation are identifiable |
| Medical dosing app | The textbook case for asking whether faulty software execution led to bodily or health damage |
This also makes one thing clear: the directive doesn’t make every hallucination liability-relevant. It isn’t bothered by every piece of nonsense that a general chatbot belches into the world like a drunk parrot with a built-in radio antenna.
But it is very much bothered by software that, in a specific safety-relevant context, prepares, calculates or triggers decisions by design.
RELEASE IS NO LONGER THE END OF THE STORY
So far we’ve crossed only the first threshold: software can be a “product”. For AI applications, nothing decisive has been settled yet.
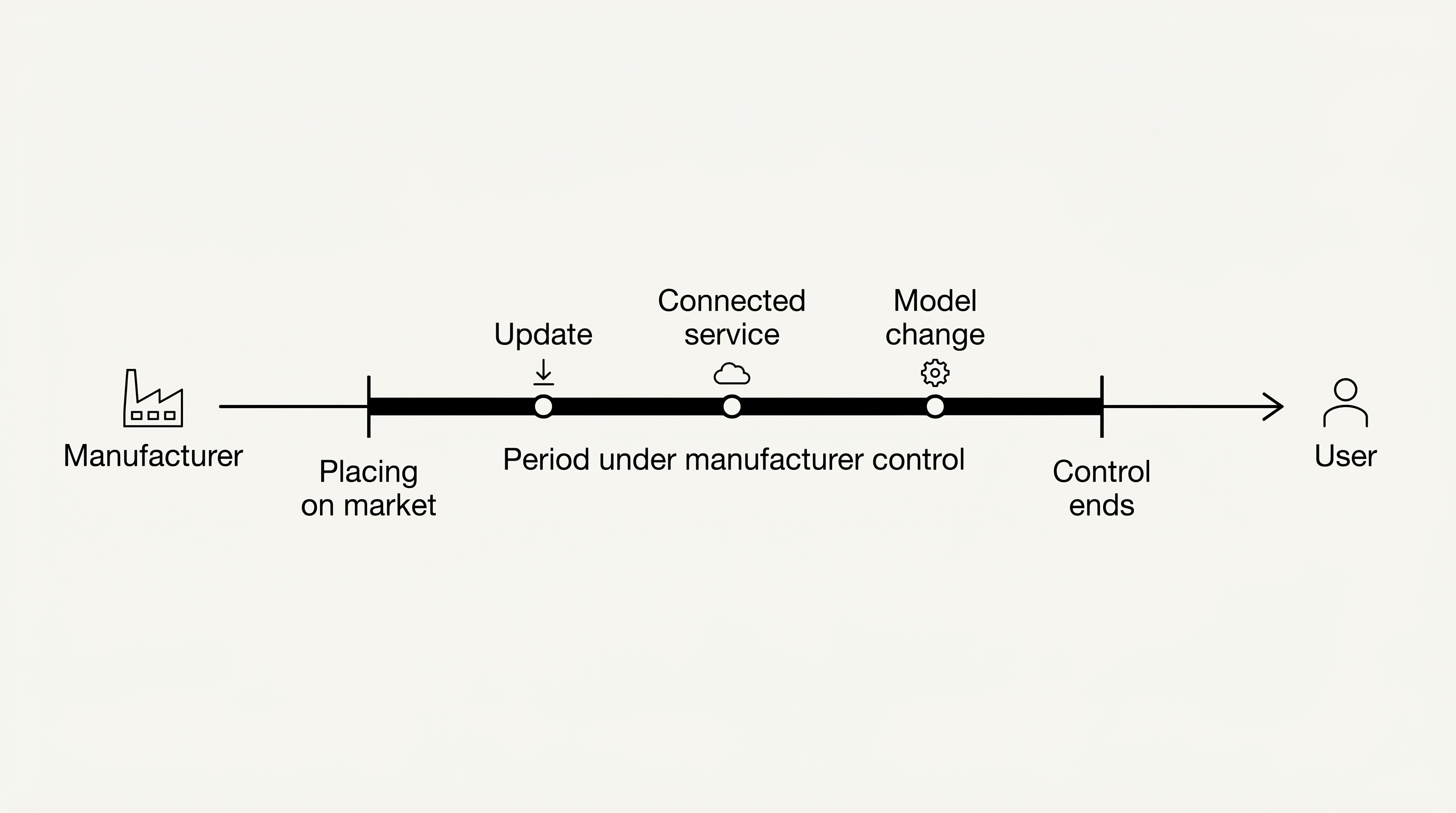
The interesting part starts after that. The directive no longer treats digital products as if they went into legal cryogenic storage the moment they were placed on the market. Software in particular tends to remain under the manufacturer’s influence — through updates and upgrades, related services, cloud components, model changes or continuous learning.
That’s the break with the classical fixed-point logic.
Under traditional product liability, placement on the market was the anchor: the product leaves the manufacturer, and the legal assessment locks onto that moment. For modern software, that’s far too short. An AI system can change after release. It can be changed by the manufacturer. It can become unsafe because updates fail to arrive. And it can depend on related services that, behind the scenes, functionally carry what the product promises out front.
The directive answers all of this with a control concept.
Article 7(2)(e) of Directive (EU) 2024/2853 requires that, when assessing defectiveness, regard be had to the moment
“at which the product was placed on the market or put into service or, where the manufacturer retains control of the product after that moment, the moment at which the product left the control of the manufacturer.”
That is the hinge clause: not just release counts, but the entire period during which the manufacturer retains control over the product.
And “control” here is not one of those vague legal terms whose edges have already frayed under the weight of competing readings. No: Article 4(5) of Directive (EU) 2024/2853 spells it out expressly. Among other things, control exists where the manufacturer authorises or consents to the integration, interconnection or supply of a component — including software updates or upgrades. Control also exists where the manufacturer is in a position to provide such updates or upgrades themselves, or to have third parties provide them.
For AI products, this is practically decisive: the ability to update is not just a comfort feature, it’s a control criterion in liability law.
- If you can retroactively update a model, you keep control.
- If you can roll out updates, you keep control.
- If you can swap out a cloud model, you keep control.
- If you present a related service as part of your product, you are not standing in some liability-free zone.
The legitimate consumer expectation is no longer pegged solely to the moment the product was placed on the market — it stretches across the entire period in which the product remains under the manufacturer’s control. The mere capability to push updates is, under Article 4(5)(b), enough to establish control.
LEARNING AFTER RELEASE

For AI systems there’s a second factor that matters for liability: the ability to learn.
Article 7(2)(c) of Directive (EU) 2024/2853 requires that account be taken of the effects of a product’s ability
“to continue to learn or to acquire new features after it has been placed on the market or put into service.”
Recital 32 spells out the expectation behind that: software and algorithms must be designed in a way that prevents dangerous product behaviour. So whoever builds a product capable of developing unexpected behaviour stays on the hook for harm-causing behaviour as well.
The fact that a learning-capable product may behave unexpectedly in use does not produce a blanket exemption from liability — but nor does it amount to a de facto ban. It shifts the standard: gains in learning and capability belong inside the safety assessment, and the system has to be built so that dangerous developments are either prevented or, at the very least, reliably detected and contained.
The point is simple: the directive does not say “AI is evil.” It says that if your system can learn or pick up new features, that very dynamic is part of the risk. The manufacturer cannot fall back on “the model just got weird after release.”
“Got weird” is not a ground for exoneration. At best it’s a bad incident-response headline.
For our insulin app, that means: if the model, the dosing logic or the parameters get changed afterwards, if the system learns from usage data, or if an update is rolled out, the risk picture moves with it. And then, in court-grade form, you have to be able to show what changed, when it changed, and whether the change was safety-relevant.
UPDATES — AND THE UPDATES THAT NEVER CAME
Now it gets even less comfortable.
Article 11(1)(c) of Directive (EU) 2024/2853 still keeps the classical defence on the books: an economic operator is not liable if it can prove that, on the balance of probabilities, the defect did not yet exist at the moment of placing on the market or putting into service, but only came about afterwards.
Sounds reassuring.
It only is, halfway.
Because Article 11(2) takes that defence away again. An economic operator is not let off the hook if the defectiveness flows from circumstances within the manufacturer’s control, in particular:
- a related service,
- software, including software updates or upgrades,
- the absence of software updates or upgrades that were necessary to maintain safety,
- a substantial modification of the product.
In practice, that is the Achilles heel of modern GenAI supply chains. If you take a base model — say, a European open-source one — fine-tune it on your own data, dress it up with system prompts, guardrails and tooling, and ship it as an API, you can’t just slide the liability back upstream to the base model’s provider. A “substantial modification” within the meaning of the directive turns the modifier into the manufacturer of the modified product.
The upstream supplier’s open-source banner is not your roof — it’s a footnote on your component list.
So what’s liability-relevant isn’t only a faulty update.
A safety-relevant update that you failed to ship can also become your problem.
Recital 51 admits that the directive does not impose any explicit obligation to provide updates or upgrades. In practice, though, if a manufacturer wants to escape a damages claim, there is often nothing left to do but ship the safety-relevant update.
If a vulnerability becomes known and the manufacturer could close it with an update, “we didn’t really feel like maintaining it any more” is not a defence. It’s more like a forensic farewell letter.
For AI applications, this means:
- Security vulnerabilities in model operation have to be watched.
- Dependencies have to be maintained.
- API changes have to be controlled.
- Model updates have to be tested.
- Rollbacks have to be possible.
- Security patches have to be documented.
- The end of support has to be thought through with liability in mind.
This isn’t compliance decor. It’s lifecycle responsibility.
RELATED SERVICES: WHEN THE APP DOESN’T WORK ALONE
Modern AI applications rarely stand on their own.
They lean on cloud inference, external models, databases, embedding services, authentication and monitoring systems, vector stores, sensors, third-party APIs. Under product liability law, none of this is treated uniformly. The directive draws a distinction: for digital services that are functionally essential, there is its own separate category — the related service.
Article 4(3) of Directive (EU) 2024/2853 defines a related service as a digital service
“that is integrated into, or interconnected with, a product in such a way that its absence would prevent the product from performing one or more of its functions.”
And Article 4(4) classifies that related service as a component.
That’s dogmatically clean enough to become practically uncomfortable.
In connected products, performance and safety no longer depend solely on the product’s own design but also on digital services. Faulty data, malfunctions of a service, or the way they interact, can cause harm. Related services can therefore be just as fundamental for the product’s safety as physical or digital components.
At the same time, the directive sets limits.
Not every service that is somehow plugged in is automatically a related service. What matters is whether the product would be unable to perform one or more of its functions without it, and whether the service was integrated or interconnected under the manufacturer’s control.
Recital 18 sharpens that control threshold: it isn’t enough that the manufacturer simply provides a technical possibility for integration, recommends specific brands, or doesn’t outright forbid certain services. Things look different where the manufacturer authorises, consents to, or presents the integration or supply as part of the product.
For our insulin app, that means:
If the app only works in conjunction with one specific cloud inference service that does the dosing calculation, that service is not interchangeable infrastructure. It is functionally required. And if the manufacturer integrates it, supplies it, or presents it as part of the product, the control logic kicks in.
At which point the later excuse —
“That wasn’t our app. That was the service behind it.”
— no longer flies.
WHY THIS IS AN ARCHITECTURE QUESTION
This is where the decisive shift happens.
The directive doesn’t just push manufacturers to take software seriously as a product. It also pushes them to take operations just as seriously, as part of the liability reality.
For AI systems, that means: the legally relevant state of the product doesn’t sit in a single release artefact, it sits in a sequence of states.
- Which model version was in production?
- Which data state was the relevant one?
- Which API version was being used?
- Which updates were rolled out, and when?
- Which security vulnerabilities were known?
- Which patches were available, or actually deployed?
- Which related services were active?
- Which changes were under the manufacturer’s control?
That’s exactly where the architectural problem starts. Or, to phrase it the way a let’s-gooo hustle coach would (natural habitat: LinkedIn): the architectureCHALLENGE. Not problem — challenge. Make a note of that, Cookie Monster will quiz you on it later. And if you don’t know it… (just go watch Predator.)
If you can’t answer those questions (model version, data state, API version, etc.) in normal operation, what you’re left with later is not just a knowledge problem — above all, it’s an evidence problem.
And that evidence problem is not an internal risk with a yellow traffic-light icon next to it. It’s the on-ramp to the next escalation level (red light, this time): disclosure obligations, presumptions, procedural disadvantages.
So the release is no longer the end of the story.
It’s the first entry in a liability log that gets written across the entire controlled lifecycle.
WHEN THE BLACK BOX GOES SILENT, PROCEDURAL LAW STEPS IN
Up to this point, all of this still sounds like product law in a digital coat of paint.
Software is a product.
Release isn’t the end any more.
Control, updates and related services count.
But the real lever sits in procedure.
A liability regime is only as sharp as its rules of evidence. If a patient is harmed but can never prove what happened inside the AI system, even the prettiest liability rules end up as a decorative paper tiger. With a little bow on it. For the legal-philosophy windowsill.
That’s exactly where the directive plants its flag.
Article 10(1) of Directive (EU) 2024/2853 sticks, at first, to the classical principle:
The claimant has to prove the defectiveness of the product, the damage suffered, and the causal link between that defectiveness and that damage.
Familiar territory.
After that, things get uncomfortable. Even more uncomfortable than before.
But Cookie Monster aside for a moment.
Wouldn’t you also want to bring a claim? Against software sold as safe and reliable, when in fact it had been hammered together by some weekend-certified vibe coder — formerly one of the better fairground boxers — between two pallets of schnapps with Lovable or whichever AI tool, and which has now drained your entire PayPal account into the hands of that famous prince in Nigeria?
Or in Wanne-Eickel. Just doesn’t have the same ring to it.
I’d be glad to be able to sue Fairground-Boxer Kalle afterwards — assuming Kalle hasn’t already burned all his cash on correction-iteration loops in Lovable (and the rest on his third pallet of schnapps).
Article 9 of Directive (EU) 2024/2853 obliges the defendant, under certain conditions, to disclose relevant evidence — once the claimant has put forward facts and evidence that sufficiently support the plausibility of the claim. Disclosure has to stay necessary and proportionate; trade secrets are protected, but not absolutely. The court can even order that evidence be presented in an easily accessible and easily understandable form.
For AI systems, that’s no sideshow.
Because “relevant evidence” can mean exactly the things that, in many projects, quietly die somewhere between DevOps, data science, security, the product owner, and “someone really should write that down”:
- Model versions
- Training and test data states
- Data lineage
- Update histories
- Test and validation protocols
- Monitoring data
- Logs
- Incident reports
- Changes to prompts, policies or system parameters
- Documentation of connected services and components
Trade secrets are no free pass. Article 9(4) and (5) does require that confidential information and trade secrets be protected. But that protection is about confidentiality within the proceedings, not about a clean getaway from disclosure altogether. To put it differently: “That’s our trade secret” is a shield. Not a cloak of invisibility.
The second lever sits in Article 10.
Defectiveness is presumed, among other situations, when the defendant fails to disclose relevant evidence under Article 9(1); when binding product safety requirements have been breached; or when the damage was caused by an obvious malfunction during reasonably foreseeable use.
For manufacturers, that is procedurally toxic.
If you don’t document, you can’t disclose later.
If you can’t disclose, you risk the presumption of defectiveness.
If you take that presumption on the chin, you are no longer arguing from a position of technical sovereignty — you’re arguing from the position of a man standing next to a burning barn with a jerry can of petrol in his hand, telling the court that, really, all of this is very complex.
Article 10(4) is sharper still.
A national court is to assume defectiveness, causation, or both, when, despite disclosure, it would be excessively difficult for the claimant — in particular due to technical or scientific complexity — to prove defectiveness or causation, and the claimant can only show that it is likely that the product was defective or that the defect caused the damage.
Recital 48 explicitly names as relevant factors: the complexity of the product, the complexity of the technology used (e.g. machine learning), the complexity of the information and data to be analysed, and the complexity of the causal link. In a case about an AI system, the claimant should specifically not be required to spell out the AI system’s particular features or their relevance for causation in detail before the court can assume that the burden has become excessive.
This is the moment when the black box switches sides.
For a long time, technical complexity in fact hurt the claimant. They could see the harm, but not the system. They could describe symptoms, but not prove the inner mechanics.
The directive does not entirely flip that situation. It doesn’t manufacture automatic liability for every digital disaster. But it does acknowledge the information asymmetry. Manufacturers know more about their systems than the people their systems harm. So: evidence has to become accessible, and presumptions have to be available.
For our insulin app, that means:
If the patient lays out that, after she used the app, a wrong dose recommendation led to bodily harm, it won’t be enough for the manufacturer to point at the complexity of the AI system. The questions get specific:
- Which version was active?
- Which input data were processed?
- Which dosing logic, or which model, was being used?
- Were any defects already known?
- Was there an update?
- Was a safety-relevant update missing?
- What logs exist?
- What tests were run?
- Was the bug reproducible?
- Which related services were involved?
If all you can answer with is a shrug, that isn’t a technical detail any more. It’s a procedural problem.
And that’s where the actual architectural point falls into place.
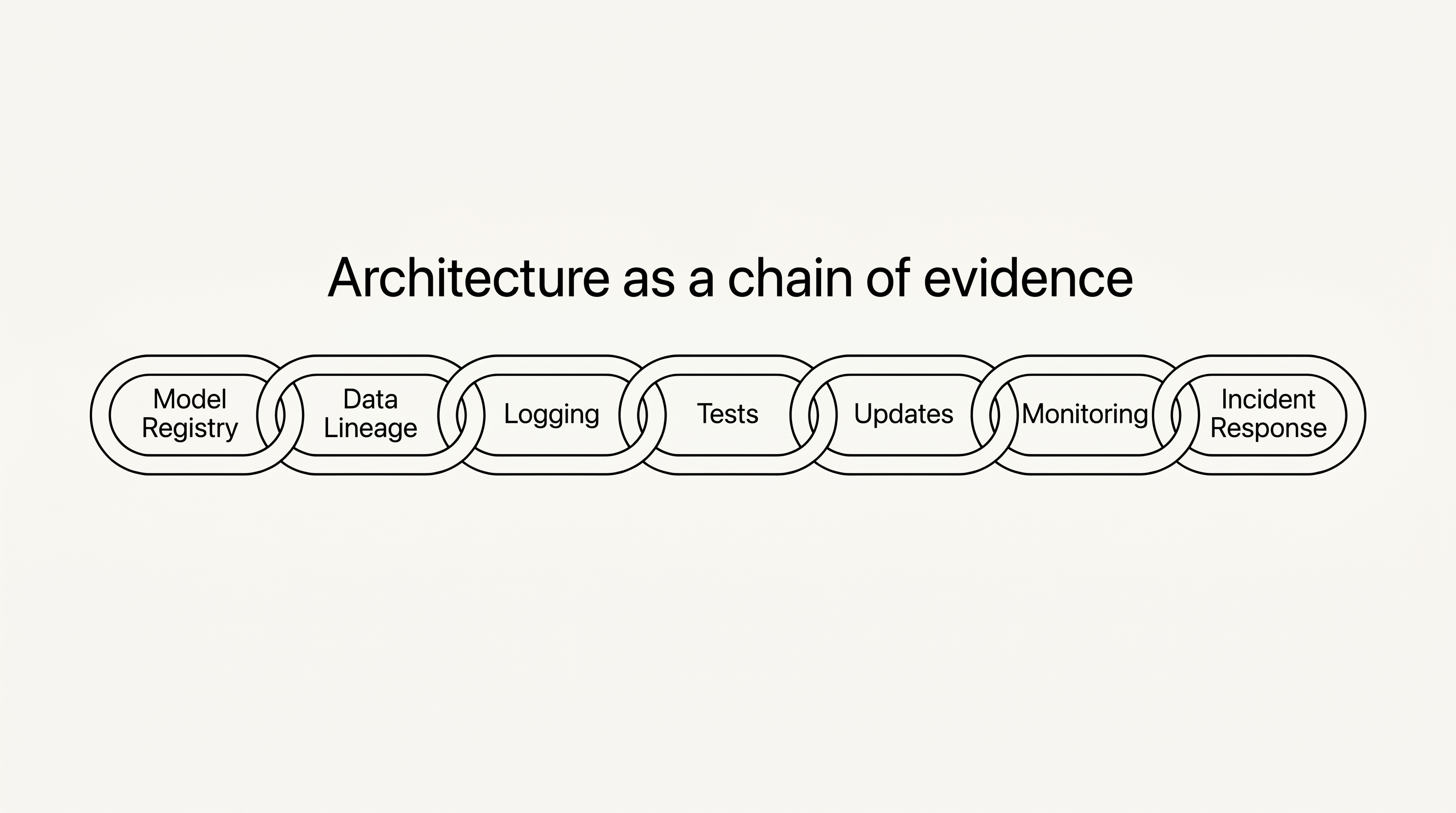
ARCHITECTURE IS THE NEW CHAIN OF EVIDENCE
The answer to this directive is not: more docs.
Nor is it: “Legal can throw together a disclaimer.”
Disclaimers are the air fresheners of compliance. They smell briefly of control, but they change nothing about the crash.
If the new product liability takes software, AI, updates, related services and technical complexity seriously, then the technical organisation has to become evidence-capable.
That doesn’t mean every AI system has to be turned into a bureaucratic cathedral of forms, process diagrams and dead SharePoint folders. It does mean that anyone building or running safety-relevant AI has to be able, later, to reconstruct what the system did and why.
For our insulin app, then, it isn’t enough to say:
We had a model.
The relevant question is:
Which model, with which data, in which version, with which update status, under which configuration, on which input, with which output, under which monitoring, and with whose sign-off?
That’s architecture. Not folklore.
For manufacturers, developers and CTOs, that translates into a concrete set of building blocks:
| BUILDING BLOCK | WHY IT BECOMES LIABILITY-RELEVANT |
|---|---|
| Model registry | Proof of which model version was in production at which time |
| Dataset versioning | Reconstruction of which data states shaped training, fine-tuning or testing |
| Data lineage | Traceability of where relevant data came from, how it was processed and how it was changed |
| Logging | Proof of inputs, outputs, errors and system states |
| Update and patch history | Evidence of which changes were rolled out — or not rolled out — and when |
| Monitoring and drift detection | Early detection of deviations during operation |
| Test protocols | Proof of validation, robustness, edge cases and regressions |
| Incident response | Structured handling of errors, damages and traceability |
| Documentation of related services | Clarification of which external services were functionally relevant and under control |
| Sign-off and accountability model | Proof of who made which operational decision |
It sounds dry. It is. But dry beats burning.
These artefacts aren’t only relevant in audits. In a dispute, they become evidence. That’s exactly where product liability law and AI architecture meet.
And it’s also where the connection to the EU AI Act sits.
The Product Liability Directive does not replace the EU AI Act. It does something different.
The EU AI Act mainly asks: may this AI system be developed, placed on the market, operated and supervised in this way? For high-risk AI systems, that means risk management, data and data governance, technical documentation, record-keeping, transparency, human oversight, accuracy, robustness and cybersecurity.
The Product Liability Directive asks about the harm:
Was the product defective, did that defectiveness cause compensable damage, and who can prove what?
Two different perspectives. But they mesh like two cogs you’d really rather not stop with your bare hand.
| FRAMEWORK | PRIMARY QUESTION | PRACTICAL RELEVANCE |
|---|---|---|
| EU AI Act | Is the AI system developed and operated in a compliant way? | Governance, documentation, risk management, logging, post-market monitoring |
| Product Liability Directive | Who is liable after a harm caused by a defective product? | Defect, damage, causation, disclosure, presumptions |
| GDPR | Were personal data processed lawfully? | Data protection, data subject rights, Art. 82 GDPR |
| CRA / product safety law | Is the product safe and cyber-resilient? | Security by design, updates, vulnerability management |
The practical effect is simple:
What looks like compliance documentation in the AI Act context can become a line of defence in a product liability suit.
More than that: anyone who actually takes the AI Act seriously — logging, risk management, technical documentation, post-market monitoring — produces precisely those artefacts whose absence Article 10(2)(a) of Directive (EU) 2024/2853 can flip into a presumption of defectiveness. If you can disclose, you don’t have to depend on the court refraining from using its presumptions.
So architecture isn’t just the chain of evidence after the harm. It’s the pre-emptive strike before the suit: clean documentation slams the procedural door in the claimant’s face before it can swing open.
Run risk management as policy alone and you’ve gained little once you’re in court. Switch logging on without being able to evaluate or explain what it shows, and you’ve built a digital aquarium: you see movement, you understand nothing. Don’t keep model versions tidy, and you can’t later prove which system actually acted.
That’s why “Compliance by Design” here is not a pretty consulting slogan.
It means: from day one, the architecture has to be built so that it doesn’t merely claim safety — it evidences safety.
For an AI-supported insulin app, that would mean things like:
- Every production model version is uniquely identifiable.
- Every dosage recommendation is tied to its input, model version, configuration and timestamp.
- Critical changes go through documented tests.
- Safety-relevant updates are versioned, reviewed and rolled out in a traceable way.
- External services aren’t just integrated — they’re controlled contractually, technically and organisationally.
- Failure cases trigger an incident process.
- Logs aren’t just present, they’re actually evaluable.
- The documentation is written so that it can be understood by someone other than the original developer, who is, by now, sitting in Bali fermenting hand-crafted kombucha.
That last point is less of a joke than it sounds.
Article 9(6) allows the court to require evidence to be produced in an easily accessible and easily understandable form, where that’s proportionate. In case of doubt, what’s at stake is not a cryptic landfill of logs, but usable clarification.
Architecture, then, becomes a translation effort:
between model and court,
between runtime and evidence,
between MLOps and liability.
If you don’t build that, you can get lucky.
But luck is not a governance strategy. At any rate, not one that survives an audit.
CONCLUSION: BUILD AI, BUILD A CHAIN OF EVIDENCE
The new Product Liability Directive is not some isolated bit of legal toy-making. It’s part of a European digital regulatory project that increasingly knits software, AI, data, cybersecurity and product responsibility together.
The decisive point isn’t only that software can now expressly count as a “product”.
What matters is what follows from that.
For AI systems, responsibility doesn’t end with release. It runs on as long as manufacturers retain control — over updates, over related services, over model changes, over safety-relevant patches, over learning features.
And when something goes wrong, gesturing at “system complexity” after the fact is not enough. Complexity is no shield. Under Articles 9 and 10 of Directive (EU) 2024/2853, complexity can be precisely the trigger for disclosure obligations to bite and for the court to start working with presumptions and procedural easing of the burden of proof.
That is the real imposition of the reform.
It demands of manufacturers, developers and CTOs not only safe products, but systems whose behaviour can be explained, reconstructed and documented to evidentiary standards in case of dispute.
For lawyers, that means: you can no longer give a defensible product-liability opinion on AI without understanding how models are deployed, versioned, monitored and updated.
For engineers, it means: architecture decisions are no longer just questions of scale, cost and performance. They co-determine whether, in a liability suit, your company can plead substantively and defend itself — or whether it ends up staring at the holes in its own logs.
The EU AI Act asks about conformity.
Product liability asks about responsibility after the harm.
Architecture decides whether an answer is even possible.
In future, whoever builds AI doesn’t just build a product.
They build a chain of evidence.
And whoever has gaps in it — Cookie Monster’s coming for you.
SOURCES
EU LEGISLATION
- Directive (EU) 2024/2853 of the European Parliament and of the Council of 23 October 2024 on liability for defective products and repealing Council Directive 85/374/EEC, OJ L 2024/2853. URL: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024L2853
- Regulation (EU) 2024/1689 (EU AI Act), OJ L 2024/1689, in force since 01.08.2024. URL: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
NATIONAL TRANSPOSITION
- BT-Drs. 21/4297 — German government draft for the transposition of Directive (EU) 2024/2853 into German law
LITERATURE
- Brenner, Raphael: “Software im Fokus der neuen Produkthaftungsrichtlinie”, Recht Digital (RDi) 2024, 345–352
- Schenk, Ulrich: “Produkthaftung für falsche KI-Antworten nach der neuen Produkthaftungs-RL?”, Legal Tech Zeitschrift (LTZ) 2025, 184–190